
Inicio rápido
 1")
This guide on how to use ScrapingBee covers every feature:
- Empezando — Create your account and get your api key
- How to Use AI Web Scraping — pull complex structured information from web pages using plain English
- How to Use Google Search API — scrape Google search results without managing proxy ips yourself
- How to Use Google Shopping Scraper — collect product listings and the extracted price for any search term
- How to Use JavaScript Web Scraping — handle javascript rendering on web pages built with React or Vue
- How to Use ChatGPT Scraper — capture responses and page source from dynamic AI chat pages
- How to Use Google News Scraper API — pull headlines and full articles through simple api requests
- How to Use Fast Data Scraping — run fast data scraping while ScrapingBee rotates proxies for you
- How to Use Programmatic Screenshot API — capture a full page screenshot of any url programmatically
- How to Use Scrape Google Jobs — gather job listings as complex structured information
Tiempo necesario: 5 minutos por función
También en esta guía: Consejos profesionales | Errores comunes | Solución de problemas | Precios | Alternativas
¿Por qué confiar en esta guía?
I have used ScrapingBee for over a year and tested every feature here. This tutorial comes from real hands-on scraping, not vendor screenshots.
 2")
ScrapingBee is a cloud based herramienta de raspado that handles the hard parts of web scraping.
It manages headless browsers and rotates proxies for you.
This guide shows you how to use every major feature step by step.
With screenshots, a simple example, and pro tips throughout.
ScrapingBee Tutorial
This complete ScrapingBee tutorial walks you through every feature, from your first api request to advanced javascript scenario tricks.
Abeja raspadora
Scrape any website without managing proxy ips or headless browsers. ScrapingBee handles javascript rendering through one simple rest api. Get 1000 free api calls to start — no credit card needed.
Getting Started with ScrapingBee
Antes de utilizar cualquier función, complete esta configuración inicial.
It takes about three minutes.
Here is a quick look at the workflow:
 4")
Ahora vamos a repasar cada paso.
Paso 1: Crea tu cuenta
Go to the ScrapingBee website and click “Sign Up”.
Enter promo code ADNAN through the referral link for extra api credit.
✓ Control: Your dashboard shows your unique api key.
Step 2: Set Up Your Code
In Python, run pip install scrapingbee or just import requests.
The requests library lets you call the api from any programming language.
✓ Control: Your environment is ready to send api requests.
Step 3: Make Your First Call
Send a request to the https://app.scrapingbee.com/api/v1/ endpoint with your api key and url.
This simple example lets you scrape web pages with a few lines of complete code.
✅ Hecho: Ya puedes utilizar cualquiera de las funciones que aparecen a continuación.
How to Use ScrapingBee AI Web Scraping
Web Scraping con IA lets you pull complex structured information from web pages using plain English.
Aquí te explicamos cómo usarlo paso a paso.
Paso 1: Obtén tu clave API
Sign up and copy your api key from the dashboard.
Step 2: Describe the Data
Add the target url and write a plain-English query.
Así es como se ve:
 5")
✓ Control: A clean JSON object appears with your fields.
Step 3: Set Extraction Rules
Adjust your extraction rules to capture each field exactly.
✅ Resultado: Structured JSON without writing css selectors by hand.
💡 Consejo profesional: Pair AI extraction with css selectors when you need precise control.
How to Use ScrapingBee Google Search API
API de búsqueda de Google lets you scrape Google search results without managing proxy ips yourself.
Aquí te explicamos cómo usarlo paso a paso.
Step 1: Choose the Endpoint
Point your request at the Google Search API.
Step 2: Set the Query
Add your keyword and a random country for local results.
Así es como se ve:
 6")
✓ Control: Ranked results return as structured data.
Step 3: Read the JSON
Parse the response with the requests library in Python.
✅ Resultado: Search data through one simple rest api call.
💡 Consejo profesional: Use country_code for premium proxy geolocation on every query.
How to Use ScrapingBee Google Shopping Scraper
Google Shopping Scraper lets you collect product listings and the extracted price for any search term.
Aquí te explicamos cómo usarlo paso a paso.
Step 1: Send a Shopping Request
Call the shopping endpoint with your product query.
Step 2: Parse the Response
Map each listing to title, link, and extracted price.
Así es como se ve:
 7")
✓ Control: Product rows return as clean JSON.
Paso 3: Exportar los resultados
Save the data to CSV for further analysis.
✅ Resultado: Live pricing data ready for any spreadsheet.
💡 Consejo profesional: Schedule runs to track the extracted price over time.
How to Use ScrapingBee JavaScript Web Scraping
JavaScript Web Scraping lets you handle javascript rendering on web pages built with React or Vue.
Aquí te explicamos cómo usarlo paso a paso.
Step 1: Enable render_js
Set render_js=true so ScrapingBee uses headless browsers.
Step 2: Wait for an Element
Tell it to wait for a particular element to load.
Así es como se ve:
 8")
✓ Control: The full page renders before extraction.
Step 3: Capture the HTML
Return the original html or raw page source after rendering.
✅ Resultado: Fully rendered web pages without web drivers to manage.
💡 Consejo profesional: Add a javascript scenario for clicking, scrolling, or form filling.
How to Use ScrapingBee ChatGPT Scraper
ChatGPT Raspador lets you capture responses and page source from dynamic AI chat pages.
Aquí te explicamos cómo usarlo paso a paso.
Step 1: Target the Page
Send the page url with render_js switched on.
Step 2: Render and Extract
Let headless scraping load the reply, then grab the texto.
Así es como se ve:
 9")
✓ Control: The rendered answer returns in the page source.
Step 3: Save the Output
Store the parsed html for later processing.
✅ Resultado: Clean text pulled from a fully dynamic page.
💡 Consejo profesional: Chain a javascript scenario to walk through multi-step prompts.
How to Use ScrapingBee Google News Scraper API
Google News Scraper API lets you pull headlines and full articles through simple api requests.
Aquí te explicamos cómo usarlo paso a paso.
Step 1: Set the News Endpoint
Aim your request at the Google News API.
Step 2: Add Filters
Filter by topic, language, or random country.
Así es como se ve:
 10")
✓ Control: Matching headlines return as structured data.
Step 3: Collect Articles
Loop through results to gather each story.
✅ Resultado: Fresh news data straight from the scrapingbee api.
💡 Consejo profesional: Rotate the country code to compare regional coverage.
How to Use ScrapingBee Fast Data Scraping
Fast Data Scraping lets you run fast data scraping while ScrapingBee rotates proxies for you.
Aquí te explicamos cómo usarlo paso a paso.
Step 1: Build Your Request
Assemble the url, api key, and parameters once.
Step 2: Run Concurrent Calls
Fire many api requests at the same time.
Así es como se ve:
 11")
✓ Control: Responses stream back in parallel.
Step 3: Check Status Codes
Confirm a 200 http code on every status code returned.
✅ Resultado: High-volume scraping handled on remote machines.
💡 Consejo profesional: ThreadPoolExecutor speeds up scraping web pages dramatically.
How to Use ScrapingBee Programmatic Screenshot API
Programmatic Screenshot API lets you capture a full page screenshot of any url programmatically.
Aquí te explicamos cómo usarlo paso a paso.
Step 1: Add the Screenshot Flag
Append screenshot=true to your api request.
Step 2: Choose Full Page
Set full_page=true to capture the entire layout.
Así es como se ve:
 12")
✓ Control: A full page image renders edge to edge.
Step 3: Download the Image
Save the returned file to disk.
✅ Resultado: Pixel-perfect captures generated on demand.
💡 Consejo profesional: The full_page parameter ensures the whole page renders first.
How to Use ScrapingBee Scrape Google Jobs
Scrape Google Jobs lets you gather job listings as complex structured information.
Aquí te explicamos cómo usarlo paso a paso.
Step 1: Call the Jobs Endpoint
Send your role and location to the jobs API.
Step 2: Filter Listings
Narrow results by title, company, or city.
Así es como se ve:
 13")
✓ Control: Job rows return as clean JSON.
Step 3: Structure the Data
Parse html fields into a tidy table.
✅ Resultado: Job data ready to parse and store.
💡 Consejo profesional: Pair with css selectors to pull custom fields.
ScrapingBee Pro Tips and Shortcuts
After testing ScrapingBee for over a year, here are my best tips for scraping websites.
Key API Parameters
| Parameter | Qué hace |
|---|---|
| render_js | Renders javascript in headless browsers |
| premium_proxy | Switches to residential proxy ips |
| country_code | Sets premium proxy geolocation by random country |
| block_ads | Lets you block ads to speed up requests |
Características ocultas que la mayoría de la gente pasa por alto
- session_id: Routes api requests through the same ip address for five minutes, so you keep the same http code and session.
- return_page_source: Returns the original html and full page source before any javascript runs.
- Custom headers and cookies: Send your own custom headers and custom cookies, or fall back to the default headers ScrapingBee generates.
- Header control: Swap an existing header for a new header, display headers generated automatically, then keep only particular headers and drop the other headers.
ScrapingBee Common Mistakes to Avoid
Mistake #1: Ignoring robots.txt before you scrape
❌ Incorrecto: Firing requests at any site you want to scrape without checking the rules first.
✅ Derecha: Check the robots.txt file and terms of service before scraping web pages.
Mistake #2: Forgetting to enable JavaScript rendering
❌ Incorrecto: Expecting dynamic content but getting an empty page source every time.
✅ Derecha: Set render_js=true so headless browsers load the full page first.
Mistake #3: Sending only the default headers
❌ Incorrecto: Relying on default headers alone, which some sites flag and block.
✅ Derecha: Send your own custom headers and a real user agent parameter when you want to scrape.
ScrapingBee Troubleshooting
Problem: Empty or partial page source
Causa: The javascript on the page never rendered, so the html came back blank.
Arreglar: Set render_js=true and wait for a particular element to load the full page.
Problem: Requests keep getting blocked
Causa: The default datacenter proxy ips were flagged by the target site.
Arreglar: Enable premium proxies to rotate in a new ip address from a random country.
Problem: You see a 401 or 403 http code
Causa: Your api key is wrong, or you are out of api credit.
Arreglar: Confirm the api key, check your status code, and top up credits if needed.
📌 Nota: If none of these fix your issue, contact ScrapingBee support.
¿Qué es ScrapingBee?
Abeja raspadora is a cloud based scraping tool that handles headless browsers and rotates proxies for you.
Think of it as a hosted browser you control through a rest api.
Mira este breve resumen:
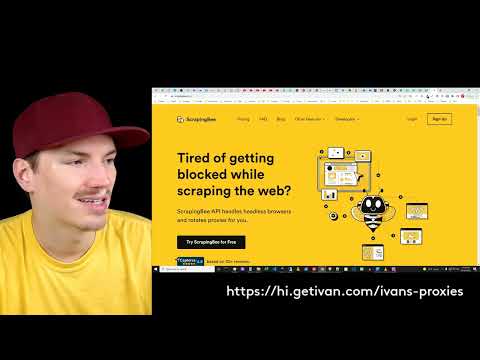
Incluye estas características clave:
- AI Web Scraping: Lets you pull complex structured information from web pages using plain English.
- Google Search API: Lets you scrape Google search results without managing proxy ips yourself.
- Google Shopping Scraper: Lets you collect product listings and the extracted price for any search term.
- JavaScript Web Scraping: Lets you handle javascript rendering on web pages built with React or Vue.
- ChatGPT Scraper: Lets you capture responses and page source from dynamic AI chat pages.
- Google News Scraper API: Lets you pull headlines and full articles through simple api requests.
- Fast Data Scraping: Lets you run fast data scraping while ScrapingBee rotates proxies for you.
- Programmatic Screenshot API: Lets you capture a full page screenshot of any url programmatically.
- Scrape Google Jobs: Lets you gather job listings as complex structured information.
Para una revisión completa, consulte nuestra ScrapingBee review.
 14")
Precios de ScrapingBee
Here is what ScrapingBee costs in 2026:
| Plan | Precio | Mejor para |
|---|---|---|
| Independiente | $49/mes | Desarrolladores independientes y proyectos pequeños |
| Puesta en marcha | $99/mes | Growing teams scaling api requests |
| Negocio | $249/mes | High-volume web scraping workloads |
| Negocios+ | $599/mes | Enterprise teams on remote machines |
Prueba gratuita: Yes — 1000 free api calls, no credit card required.
Garantía de devolución de dinero: Cancel anytime; billing is monthly with no lock-in.
 15")
💰 Mejor relación calidad-precio: Startup — the best balance of api credit and price for most teams.
ScrapingBee frente a alternativas
How does ScrapingBee compare? Here is the competitive landscape:
Mira esta comparación:
| Herramienta | Mejor para | Precio | Clasificación |
|---|---|---|---|
| Abeja raspadora | JavaScript rendering via one rest api | $49/mes | ⭐ 4.5 |
| Apificar | Ready-made scraper actors | Varía | ⭐ — |
| ScrapeGraphAI | AI-driven extraction rules | Varía | ⭐ — |
| Datos brillantes | Enterprise proxy ips | Varía | ⭐ — |
| Navegar AI | No-code point and click | Varía | ⭐ — |
| Oxylabs | Premium enterprise proxies | Varía | ⭐ — |
| Datos de Thor | Budget proxy network | Varía | ⭐ — |
| Zyte | Developer scraping api | Varía | ⭐ — |
| Raspador web.io | Browser extension capture | Varía | ⭐ — |
| Raspador de helio | Desktop site mapping | Varía | ⭐ — |
| Firecrawl | LLM-ready markdown | Varía | ⭐ — |
Selecciones rápidas:
- Mejor en general: ScrapingBee — one rest api for rendering, search, and screenshots.
- Mejor presupuesto: ThorData — cheap proxy ips for simple scraping purposes.
- Ideal para principiantes: Browse AI — no code and no programming language needed.
- Ideal para empresas: Bright Data — built for huge, compliant scraping operations.
🎯 ScrapingBee Alternatives
¿Buscas alternativas a ScrapingBee? Aquí tienes las mejores opciones:
- 🚀 Apify: A full scraping platform with ready-made actors and a generous free tier for testing ideas fast.
- 🧠 ScrapeGraphAI: An AI-first scraper that turns plain prompts into extraction rules for complex structured information.
- 🏢 Datos brillantes: Enterprise-grade proxy ips and datasets built for very large scraping operations and strict compliance.
- 👶 Explorar la IA: A no-code tool that records your clicks to build scrapers without writing any code.
- 🔒 Oxylabs: A premium proxy and scraper API provider with strong reliability for demanding enterprise workloads.
- 💰 ThorData: A budget-friendly proxy network covering residential and datacenter proxy ips for everyday scraping jobs.
- 🔧 Zyte: A developer-focused scraping API, formerly Scrapinghub, with smart bans handling and clean page source.
- 🎨 Webscraper.io: A browser-extension scraper that builds sitemaps visually inside Chrome for point-and-click data capture.
- 💼 Helium Scraper: A desktop scraping app for Windows that maps complex sites without any cloud dependency.
- ⚡ Firecrawl: An AI crawler that converts whole sites into clean markdown for feeding large language models.
Para ver la lista completa, consulte nuestra Alternativas a ScrapingBee guía.
⚔️ Comparación de ScrapingBee
Here is how ScrapingBee stacks up against each competitor:
- ScrapingBee vs Apify: Apify offers a marketplace of scrapers; ScrapingBee wins on simple rest api access and faster setup.
- ScrapingBee vs ScrapeGraphAI: ScrapeGraphAI leans fully on AI; ScrapingBee gives you both AI extraction and raw css selectors.
- ScrapingBee vs Bright Data: Bright Data scales to enterprise; ScrapingBee is cheaper and simpler for small to mid teams.
- ScrapingBee vs Browse AI: Browse AI suits non-coders; ScrapingBee fits developers who want a rest api and full control.
- ScrapingBee vs Oxylabs: Oxylabs targets large enterprises; ScrapingBee offers lower entry pricing and an easier learning curve.
- ScrapingBee vs ThorData: ThorData competes on proxy price; ScrapingBee bundles rendering, screenshots, and AI into one api.
- ScrapingBee vs Zyte: Zyte has deep developer roots; ScrapingBee is friendlier for quick projects and small teams.
- ScrapingBee vs Webscraper.io: Webscraper.io runs in the browser; ScrapingBee handles javascript rendering server-side at real scale.
- ScrapingBee vs. Helium Scraper: Helium Scraper is desktop-only; ScrapingBee runs in the cloud so you skip web drivers entirely.
- ScrapingBee vs Firecrawl: Firecrawl targets LLM pipelines; ScrapingBee covers broader scraping with screenshots and search APIs.
Start Using ScrapingBee Now
You learned how to use every major ScrapingBee feature:
- ✅ AI Web Scraping
- ✅ Google Search API
- ✅ Google Shopping Scraper
- ✅ JavaScript Web Scraping
- ✅ ChatGPT Scraper
- ✅ Google News Scraper API
- ✅ Fast Data Scraping
- ✅ Programmatic Screenshot API
- ✅ Scrape Google Jobs
Siguiente paso: Elige una función y pruébala ahora.
Most people start with AI Web Scraping.
A popular first project is creating an OLX scraper to pull listings.
During development ScrapingBee runs the browser on remote machines for you.
Explore further features once your first OLX scraper works.
It takes less than five minutes to scrape your first page.
Preguntas frecuentes
¿Cómo funciona ScrapingBee?
ScrapingBee is a cloud based scraping tool. You send a request with your api key and a url, and it returns the page using headless browsers while it rotates proxies for you.
¿Cuánto cuesta ScrapingBee?
Plans start at $49/month for Freelance, then $99 Startup, $249 Business, and $599 Business+. A free trial gives you 1000 api calls to test scraping purposes.
¿Es ilegal el web scraping?
Scraping public web pages is generally legal. Always check a site’s robots.txt and terms first, avoid personal data, and respect rate limits to stay on the safe side.
Does ScrapingBee support JavaScript rendering?
Yes. Set render_js=true and ScrapingBee loads web pages in headless browsers. This javascript rendering works on sites built with React or Vue out of the box.
Which programming language does ScrapingBee support?
Any. ScrapingBee is a rest api, so you call it from Python, Node, PHP, or any language. In Python just import requests and send your api requests.


 17")
 18")

 20")

 22")
 23")
 24")
 25")
 26")
 27")
