
Snelstart
 1")
This guide covers every Helium Scraper feature:
- Aan de slag — Account aanmaken en basisinstellingen
- How to Use Fast Extraction — Pull data from any web page in simple steps
- How to Use Simple Workflow — Build a no-code workflow to scrape any site
- How to Use Scale on Demand — Scale on demand with proxy integration and proxies
- How to Use Capture Complex Data — Capture complex, nested data and JavaScript content
- How to Use Install Anywhere — Install on any computer and run scraping locally
Benodigde tijd: 5 minuten per film
Ook in deze handleiding: Professionele tips | Veelgemaakte fouten | Probleemoplossing | Prijzen | Alternatieven
Waarom zou je deze gids vertrouwen?
I’ve used Helium Schraper for two years and tested every feature covered here. This tutorial comes from real hands-on experience — not marketing fluff or vendor screenshots.
 2")
Helium Scraper is a desktop, no-code scraper built for small to medium gegevens extraction tasks.
But most users only scratch the surface of what this point-and-click tool can do.
This guide shows you how to use Helium Scraper and every major feature.
Stap voor stap, met screenshots en professionele tips.
Handleiding voor het schrapen van helium
This complete Helium Scraper tutorial walks you through every feature, from setup to advanced tips that turn you into a power user who can extract data fast.
Heliumschraper
Scrape websites visually without writing code. Helium Scraper uses point-and-click selection to extract data from any site on your own computer. One-time desktop purchase — no subscriptions.
Getting Started with Helium Scraper
Voordat u een functie kunt gebruiken, moet u deze eenmalige installatie voltooien.
Het duurt ongeveer 3 minuten.
Watch this quick personal experience walkthrough first:
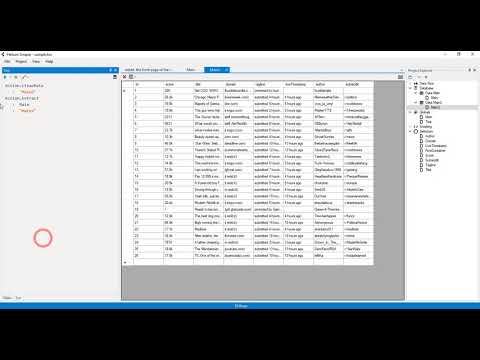
Laten we nu elke stap eens doornemen.
Stap 1: Downloaden en installeren
Go to the Helium Scraper website and pick your plan.
Download the installer, then install it on your computer.
✓ Controlepunt: The app icon appears on your desktop.
Stap 2: Openen en inloggen
Open the app and confirm your license to activate it.
Helium Scraper runs locally, so no cloud account is needed.
Zo ziet het dashboard eruit:
 4")
✓ Controlepunt: You should see the main menu and built-in web browser.
Stap 3: Maak je eerste project aan.
Click Create to start a new project for your target site.
Enter the URL you want to scrape into the built-in browser.
✅ Klaar: Je bent klaar om een van de onderstaande functies te gebruiken.
How to Use Helium Scraper Fast Extraction
Fast Extraction lets you pull data from any web page in just a few simple steps.
Hieronder leggen we stap voor stap uit hoe je het gebruikt.
Helium Scraper works on any site, from a Google or Bing search engine results page to a product catalog.
Laten we nu elke stap eens nader bekijken.
Step 1: Open the Built-in Browser
Navigate to the target site inside the built-in browser.
Enter the URL you want to scrape and load the page.
Step 2: Select Your Data Points
Ctrl+click the elements you want, like product titles or prices.
Zo ziet het eruit:
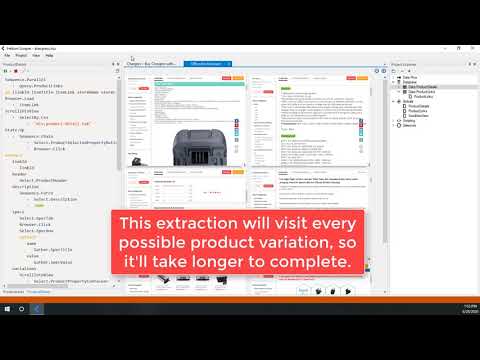
✓ Controlepunt: Selected elements turn highlighted in the browser.
Step 3: Run and Export
Press extract, then export your data to Excel, CSV, JSON, or SQLite.
✅ Resultaat: You extracted clean data from the site in minutes.
💡 Pro-tip: Enable selection mode and Ctrl+click similar items to teach the tool a pattern fast.
How to Use Helium Scraper Simple Workflow
Simple Workflow lets you build a no-code scraping workflow without writing code or coding skills.
Hieronder leggen we stap voor stap uit hoe je het gebruikt.
Laten we nu elke stap eens nader bekijken.
Step 1: Define Your Kinds
Create kinds to mark the data elements you want to extract.
Kinds define product titles, prices, or any field on the page.
Stap 2: Acties toevoegen
Add actions like clicking and navigating through pagination.
Zo ziet het eruit:
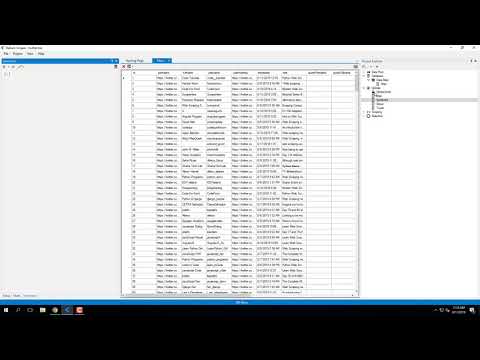
✓ Controlepunt: Your workflow runs through pages without errors.
Step 3: Validate the Workflow
Test your kinds across different pages to confirm accurate results.
✅ Resultaat: You built a repeatable extraction process with point-and-click selection.
💡 Pro-tip: The drag-and-drop bouwer is helpful for beginners; create repeat loops within actions to handle large-scale extraction.
How to Use Helium Scraper Scale on Demand
Scale on Demand lets you scale large projects with proxy integration to avoid rate limits and captchas.
Hieronder leggen we stap voor stap uit hoe je het gebruikt.
Laten we nu elke stap eens nader bekijken.
Stap 1: Open de proxy-instellingen
Open the settings menu and find the proxy integration section.
Helium Scraper can integrate with proxy services to bypass captchas and IP blocks.
Stap 2: Voer de proxygegevens in.
Enter the proxy address and port, then confirm and enable proxies.
Zo ziet het eruit:
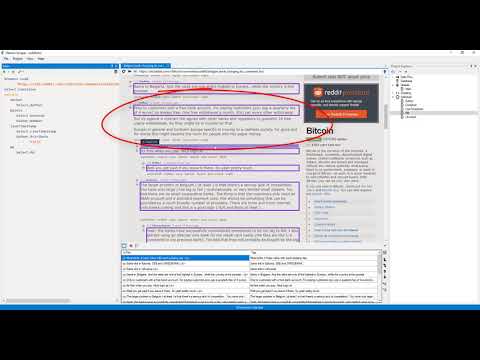
✓ Controlepunt: Your requests route through the chosen exit node.
Step 3: Pick an Exit Node
Choose a US exit node or any location with residential proxies.
An exit node from a specific country helps you scrape geo-targeted data.
✅ Resultaat: You scrape at scale without hitting the 500-600 requests per hour limit.
💡 Pro-tip: Use rotational proxies and sticky sessions for consistent, large scraping projects.
How to Use Helium Scraper Capture Complex Data
Capture Complex Data lets you capture complex, nested data from modern sites that rely on JavaScript.
Hieronder leggen we stap voor stap uit hoe je het gebruikt.
Laten we nu elke stap eens nader bekijken.
Step 1: Enable JavaScript Handling
Let Helium Scraper navigate and click elements to render JavaScript.
The tool also downloads images while it works through the page.
Step 2: Set Up Nested Extraction
Define nested kinds to extract data inside lists or tables.
Zo ziet het eruit:
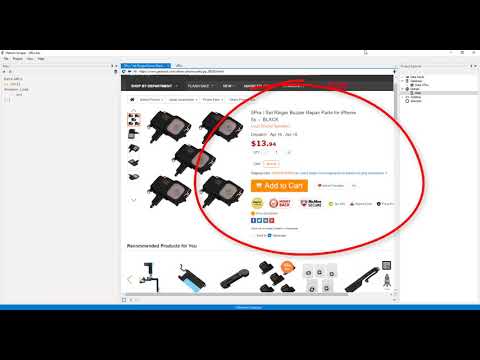
✓ Controlepunt: Nested fields appear correctly in your data preview.
Step 3: Use Custom Code
Add custom JavaScript and SQL for advanced data extraction tasks.
✅ Resultaat: You captured complex, structured web data from a dynamic site.
💡 Pro-tip: Validate nested kinds on several example pages before running the full job.
How to Use Helium Scraper All-in-one Installer
Install Anywhere lets you install the desktop app on any computer and run scraping locally.
Hieronder leggen we stap voor stap uit hoe je het gebruikt.
Laten we nu elke stap eens nader bekijken.
Step 1: Download the Installer
Download the installer from the website and run the setup.
The install process is straightforward and finishes in minutes.
Step 2: Activate Your License
Open the app and confirm your license with your password.
Zo ziet het eruit:
✓ Controlepunt: The app launches and loads the built-in browser.
Step 3: Check System Resources
Make sure your computer has enough resources for large jobs.
Helium Scraper runs locally and may need significant desktop resources.
✅ Resultaat: You have a local scraper ready on your own machine.
💡 Pro-tip: For heavy jobs, close other apps so more resources go to the extraction process.
Helium Scraper Pro Tips and Shortcuts
After testing Helium Scraper for two years, here are my best tips for faster data extraction.
Toetsenbord sneltoetsen
| Actie | Snelkoppeling |
|---|---|
| Select an element | Ctrl + Klikken |
| Expand a selection | Ctrl + Shift + Click |
| Run extraction | F5 |
| Open project settings | Ctrl + , |
Verborgen functies die de meeste mensen over het hoofd zien
- Custom JavaScript and SQL: Add code for advanced extraction the point-and-click menu cannot reach.
- US exit node selection: Pick proxies from a specific location to scrape geo-locked search engine and site data.
- Repeat loops: Create loops within actions to navigate pagination and extract large lists automatically.
Helium Scraper Common Mistakes to Avoid
Mistake #1: Skipping Proxy Integration
❌ Fout: Sending hundreds of requests from one IP and hitting captchas and rate limits.
✅ Rechts: Set up proxy integration with rotational proxies to avoid the 500-600 requests per hour ceiling.
Mistake #2: Not Validating Your Kinds
❌ Fout: Trusting one page and assuming the kind works across the whole site.
✅ Rechts: Test each kind on several example pages to confirm accurate data identification.
Mistake #3: Ignoring Computer Resources
❌ Fout: Running a huge job while many other apps compete for limited resources.
✅ Rechts: Close other programs so the extraction process gets the resources it needs.
Helium Scraper Troubleshooting
Problem: Pages Load Blank
Oorzaak: The site relies on JavaScript that has not finished rendering.
Repareren: Let the tool navigate and click elements so the page loads fully before you select data.
Problem: Getting Blocked or Captchas
Oorzaak: Too many requests from one IP triggered the site’s defenses.
Repareren: Enable proxies in settings, enter the address and port, and pick a fresh exit node.
Probleem: Onjuiste gegevens geëxtraheerd
Oorzaak: Your kind matched the wrong elements on some pages.
Repareren: Re-select with Ctrl+click and validate the kind across different pages of the site.
📌 Opmerking: If none of these fix your issue, check the docs or contact Helium Scraper support and community.
Wat is een heliumschraper?
Heliumschraper is a desktop, no-code scraper that lets you extract data from the web visually.
Think of it like a smart highlighter — you point, click, and it collects the data for you.
The main difference from cloud tools is that it runs locally, which is true for every scraping job and ideal for small, lightweight use cases.
Bekijk dit korte overzicht:
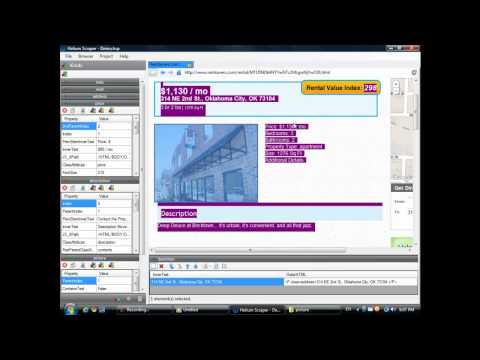
Het omvat de volgende belangrijke kenmerken:
- Fast Extraction: Pull data from any page in simple steps
- Simple Workflow: Build a no-code workflow without coding skills
- Scale on Demand: Scale with proxy integration and a US exit node
- Capture Complex Data: Capture complex, nested data and JavaScript content
- Install Anywhere: Install and run scraping locally on any computer
Voor een volledige recensie, zie onze Helium Scraper review.
 5")
Prijsbepaling van heliumschrapers
Here’s what Helium Scraper costs in 2026:
| Plan | Prijs | Het beste voor |
|---|---|---|
| Basis | $99 | Individuals and small scraping tasks |
| Professioneel | $199 | Freelancers running regular projects |
| Bedrijf | $399 | Teams with bigger data needs |
| Onderneming | $699 | Heavy, large-scale scraping |
Gratis proefperiode: Yes — a free trial lets you test the tool before you buy.
Geld-terug-garantie: Pricing is a one-time desktop purchase, not a subscription.
 6")
💰 Beste prijs-kwaliteitverhouding: Professional — the best plan for most freelancers who scrape regularly.
Heliumschraper versus alternatieven
How does Helium Scraper compare? Here’s the competitive landscape:
| Hulpmiddel | Het beste voor | Prijs | Beoordeling |
|---|---|---|---|
| Heliumschraper | No-code local scraping | $99 eenmalig | ⭐ 3,5 |
| Octoparse | Visual cloud scraping | $99/maand | ⭐ 4.3 |
| ParseHub | Beginners | $189/maand | ⭐ 4.2 |
| Scrapy | Developers | Vrij | ⭐ 4,5 |
| Schraperbij | API and scale | $49/maand | ⭐ 4.4 |
| Bright Data | Enterprise proxies | $499/maand | ⭐ 4.6 |
Snelle keuzes:
- Beste overall: Helium Scraper — visual, no-code, and a one-time price.
- Beste budget: Scrapy — free and open-source for those writing code.
- Het meest geschikt voor beginners: ParseHub — simple and straightforward to learn.
- Best for scale: ScrapingBee — a cloud API for automated, large jobs.
🎯 Alternatieven voor heliumschrapers
Looking for Helium Scraper alternatives? Here are the top options:
- 🚀 Octoparse: A cloud-based visual scraper with scheduling and automatisering that runs jobs without keeping your computer on.
- 👶 ParseHub: A beginner-friendly tool with a simple point-and-click setup, ideal for users new to data extraction.
- 🔧 Scrapy: A free, open-source framework for developers comfortable writing code and building custom scraping projects.
- ⚡ ScrapingBee: A cloud web scraping API that renders JavaScript and handles proxies and captchas at scale.
- 🏢 Heldere gegevens: An enterprise platform with massive proxy networks and a US exit node for geo-targeted extraction.
Voor de volledige lijst, zie onze Helium Scraper alternatives gids.
⚔️ Heliumschraper vergeleken
Here’s how Helium Scraper stacks up against each competitor:
- Heliumschraper versus Octoparse: Helium Scraper wins on price with a one-time fee; Octoparse wins on cloud scheduling and parallel runs.
- Helium Scraper versus ParseHub: Both are beginner-friendly; Helium Scraper is better for local, lightweight scraping without monthly costs.
- Heliumschraper versus Scrapy: Scrapy wins for coders building custom scrapers; Helium Scraper wins for no-code visual extraction.
- Helium Scraper versus ScrapingBee: ScrapingBee excels at automation and scale; Helium Scraper is better for quick local jobs without coding.
- Helium Scraper versus Bright Data: Bright Data leads on proxies and enterprise scale; Helium Scraper is simpler and far cheaper for small tasks.
Start Using Helium Scraper Now
You learned how to use every major Helium Scraper feature:
- ✅ Fast Extraction
- ✅ Simple Workflow
- ✅ Scale on Demand
- ✅ Capture Complex Data
- ✅ Install Anywhere
Volgende stap: Kies één functie en probeer die nu uit.
Most people start with Fast Extraction.
Het duurt minder dan 5 minuten.
Veelgestelde vragen
How do I use Helium Scraper?
Install the desktop app, open the built-in browser, Ctrl+click the data you want to create kinds, then run and export your extraction to Excel, CSV, JSON, or SQLite.
Does Helium Scraper need coding skills?
No. Helium Scraper is a no-code, point-and-click tool. You select data visually without writing code, though custom JavaScript and SQL are available for advanced data extraction.
How does proxy integration work in Helium Scraper?
Open settings, enter the proxy address and port, confirm, and enable proxies. Pick an exit node like a US location to scrape geo-targeted data and avoid captchas.
Is Helium Scraper good for large projects?
It suits small to medium projects. For large jobs, use rotational proxies to avoid the 500-600 requests per hour limit, since the tool runs locally and uses your resources.
Can Helium Scraper handle JavaScript sites?
Yes. It navigates and clicks elements to render JavaScript and download images, letting you extract complex, nested data from modern dynamic websites.

 7")
 8")
 9")
 10")


 13")
 14")
 15")

 17")
 18")
